The Problem: When Your Job is Too Big
Have you tried to create a workflow that needs to process 1000 customer records, send 100 page PDF to the LLM, generate 50 reports, or handle a massive dataset? You might run into these issues:- Timeouts: Workflows can only run for 10 minutes total
- Complexity: Large workflows become hard to debug and maintain
- Failure Risk: If step 47 out of 50 fails, you lose all your progress
- Resource Limits: Processing everything at once can overwhelm systems such as LLMs that can quickly hit context window limits with large amounts of data
The Solution: The Producer-Consumer Pattern
Think of it like a factory assembly line with three specialized stations:- Producer (Station 1): Receives the big task and breaks it into individual items in a single batch
- Consumer (Station 2): Processes each batch item one at a time
- Aggregator (Station 3): Collects all the completed batch items and creates the final result
How it works
Workflow 1: Producer
Purpose: Break down your big job into individual items in a single batch This workflow:- Receives your initial request (e.g., “process 500 customers”)
- Uses the Batch service to create a batch with unique batchId
- Breaks the work into individual batch items
- Places all items into a Queue for parallel processing
- Assigns the Consumer automation to process each batch item
Workflow 2: Consumer
Purpose: Process individual batch items and store results This workflow:- Gets triggered for each batch item from the queue
- Processes one batch item at a time (e.g., one customer record)
- Stores results in datastore or filestore with batchId metadata
- Marks the batch item as complete
- Handles retries automatically based on queue configuration
Workflow 3: Aggregator
Purpose: Compile final results when all batch items are done This workflow:- Gets triggered automatically when the batch completes (using completion actions)
- Retrieves all batch results from datastore/filestore using the batchId
- Compiles the final output (reports, summaries, etc.)
- Sends notifications or delivers final results
- Cleans up temporary data if needed
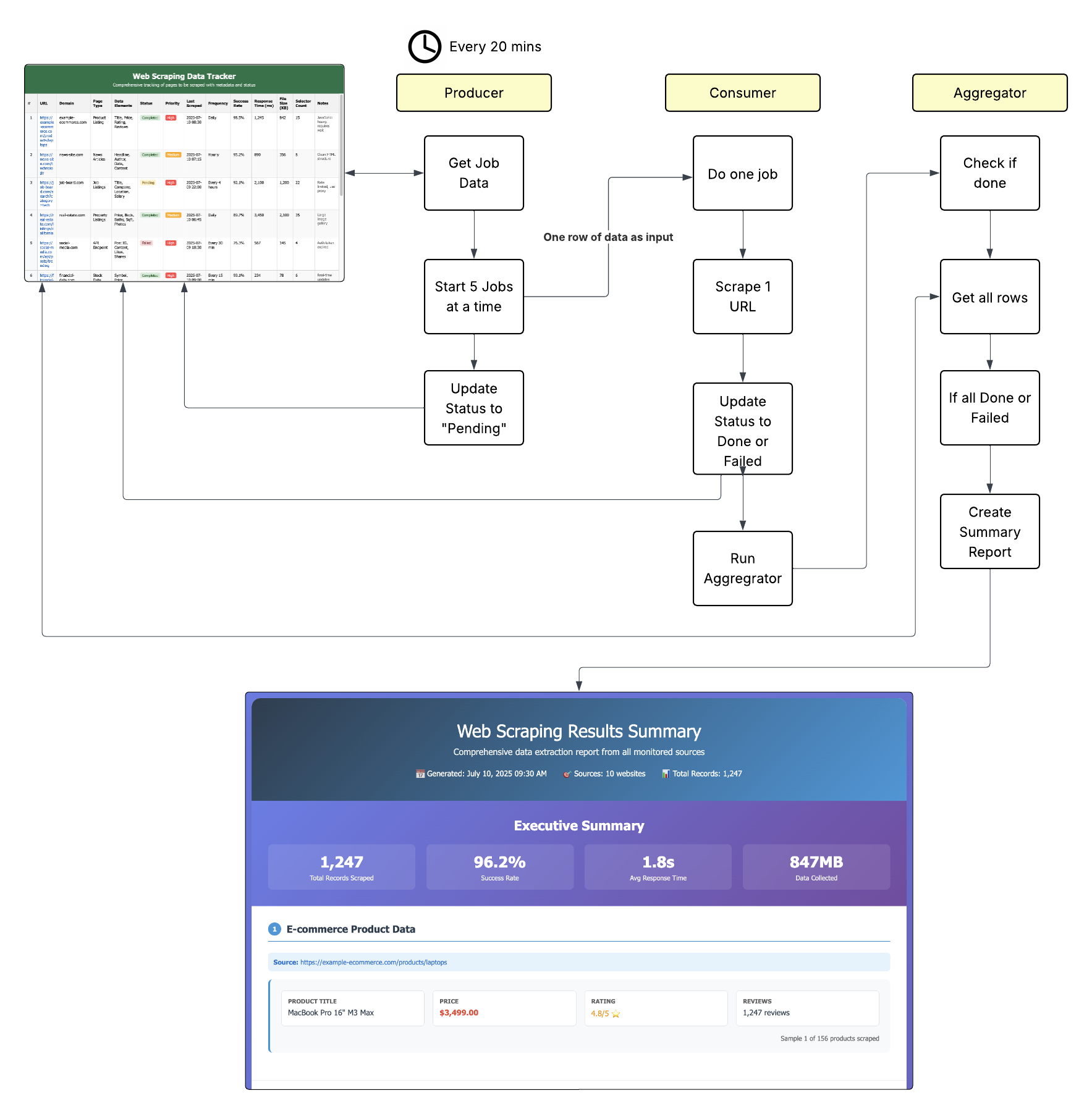
Note: The easiest way to set up this pattern is to put your producer on a scheduled trigger. Every time it runs it will get a new batch of jobs. Of course, it’ll also be running when you have no jobs, but that’ll be a simple check and done. The more advanced way to set this up is by creating batch jobs via the Queue service, where the aggregator is set to run on batch done.
Benefits of the Producer-Consumer Pattern
🔄 Reliability
- Each workflow is simple and focused
- Failed items retry automatically based on queue max retries
- Batch tracking shows exactly what’s complete
- No risk of losing all progress
🐛 Easier Debugging
- Test each workflow independently
- Clear separation of concerns
- Detailed queue monitoring via Monitor tab
- Easy to identify bottlenecks
⚡ Better Performance
- Consumers run in parallel based on queue concurrency settings
- Automatic concurrency management
- No resource bottlenecks
- Scales to handle any volume
📊 Progress Tracking
- Real-time batch monitoring
- See exactly which items are done
- Queue dashboard shows pending and running jobs
- Automatic retry handling
🧠 LLM Optimization
- Works within LLM context window limits
- Processes large datasets by breaking them into manageable chunks
- Avoids overwhelming AI models with too much data at once
- Enables consistent processing quality across all items
Best Practices
- Start Small: Test with a few batch items before scaling
- Configure Queues: Set appropriate concurrency and retry limits for your use case
- Monitor Performance: Use queue dashboard to optimize processing
- Handle Failures: Design consumer to be fault-tolerant
- Store Results: Use datastore for metadata, filestore for large outputs (always include batchId for easy aggregation)
- Set Completion Actions: Configure batch completion to trigger your aggregator workflow
- Clean Up: Use aggregator to archive or delete temporary data
Example Use Case: Summarizing a 1000 page document
Using the Producer/Consumer Pattern for Large Document Processing where the content exceeds the LLM context window.1. Producer Workflow: Split and Batch
Purpose: Break your 1000-page document into manageable chunks and create a batch job. This workflow should:- Use the
/pdf-splitterskill to split your large document into smaller chunks; each chunk will be deposited into the Filestore collection of your choice. - Create a new Batch Job where each input will have the name of the file to process.
2. Consumer Workflow: Summarize Chunks
Purpose: Process individual document chunks and extract summaries This workflow gets triggered for each chunk and should:- Receive one document chunk filename
- Use
/pdf-analysisor LLM of your choice to process the chunk with an LLM - Store the summary results in the datastore with the batchId for later aggregation
3. Aggregator Workflow: Stitch and Smooth
Purpose: Combine all chunk summaries into a comprehensive final summary This workflow gets triggered when the batch completes and should:- Retrieve all chunk summaries from the datastore using the batchId
- Use an LLM to synthesize the individual summaries into a cohesive final summary
- Deliver the final result
Note: This pattern is also known as the Work Queue Pattern, Batch Processing Pattern, or Fan-out/Fan-in Pattern in computer science. For more details on Queue and Batch service configuration, see the Queue Service documentation.
Questions? Reach out on Discord https://discord.com/invite/HaDg7R4VZG